Stat-Ease Blog

Categories
The Importance of Center Points in Central Composite Designs
A central composite design (CCD) is a type of response surface design that will give you very good predictions in the middle of the design space. Many people ask how many center points (CPs) they need to put into a CCD. The number of CPs chosen (typically 5 or 6) influences how the design functions.
Two things need to be considered when choosing the number of CPs in a central composite design:
1) Replicated center points are used to estimate pure error for the lack of fit test. Lack of fit indicates how well the model you have chosen fits the data. With fewer than five or six replicates, the lack of fit test has very low power. You can compare the critical F-values (with a 5% risk level) for a three-factor CCD with 6 center points, versus a design with 3 center points. The 6 center point design will require a critical F-value for lack of fit of 5.05, while the 3 center point design uses a critical F-value of 19.30. This means that the design with only 3 center points is less likely to show a significant lack of fit, even if it is there, making the test almost meaningless.
TIP: True “replicates” are runs that are performed at random intervals during the experiment. It is very important that they capture the true normal process variation! Do not run all the center points grouped together as then most likely their variation will underestimate the real process variation.
2) The default number of center points provides near uniform precision designs. This means that the prediction error inside a sphere that has a radius equal to the ±1 levels is nearly uniform. Thus, your predictions in this region (±1) are equally good. Too few center points inflate the error in the region you are most interested in. This effect (a “bump” in the middle of the graph) can be seen by viewing the standard error plot, as shown in Figures 1 & 2 below. (To see this graph, click on Design Evaluation, Graph and then View, 3D Surface after setting up a design.)
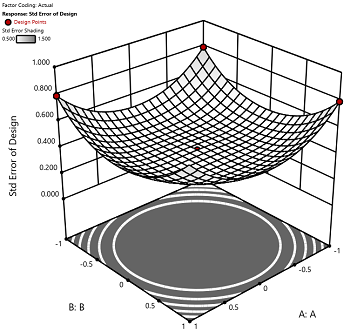
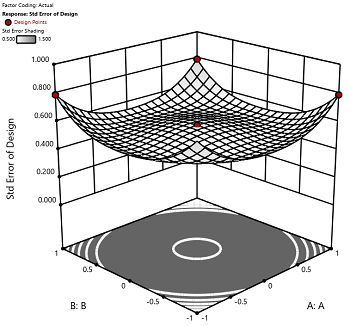
Figure 1 (left): CCD with the 6 center points (5-6 recommended). Figure 2 (right): CCD with only 3 center points. Notice the jump in standard error at the center of figure 2.
Ask yourself this—where do you want the best predictions? Most likely at the middle of the design space. Reducing the number of center points away from the default will substantially damage the prediction capability here! Although it can seem tedious to run all of these replicates, the number of center points does ensure that the analysis of the design can be done well, and that the design is statistically sound.
New Software Features! What's in it for You?
There are a couple features in the latest release of Design-Expert and Stat-Ease 360 software programs (version 22.0) that I really love, and wanted to draw your attention to. These features are accessible to everyone, no matter if you are a novice or an expert in design of experiments.
First, the Analysis Summary in the Post Analysis section: This provides a quick view of all response analyses in a set of tables, making it easy to compare model terms, statistics such as R-squared values, equations and more. We are pleased to now have this feature that has been requested many times! When you have a large number of responses, understanding the similarities and differences between the model may lead to additional insights to your product or process.
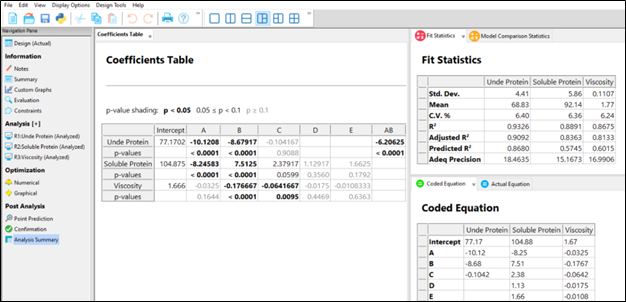
Second, the Custom Graphs (previously Graph Columns): Functionality and flexibility have been greatly expanded so that you can now plot analysis or diagnostic values, as well as design column information. Customize the colors, shapes and sizes of the points to tell your story in the way that makes sense to your audience.
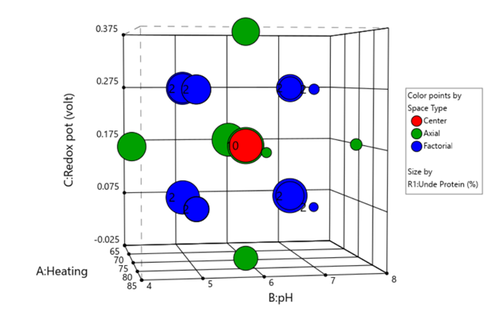
Figure 1 (left) shows the layout of points in a central composite design, where the points are colored by the their space point type (factorial, axial or center points) and then sized by the response value. We can visualize where in the design space the responses are smaller versus larger.
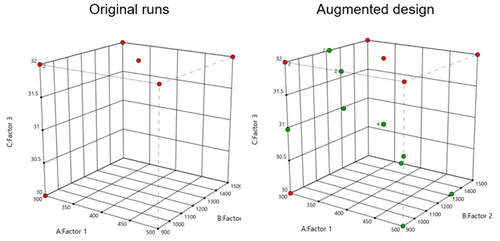
In Figure 2 (right), I had a set of existing runs that I wanted to visualize in the design space. Then I augmented the design with new runs. I set the Color By option to Block to clearly see the new (green) runs that were added to the design space.
These new features offer many new ways to visualize your design, response data, and other pieces of the analysis. What stories will you tell?
Augmenting One-Factor-at-a-Time Data to Build a DOE
I am often asked if the results from one-factor-at-a-time (OFAT) studies can be used as a basis for a designed experiment. They can! This augmentation starts by picturing how the current data is laid out, and then adding runs to fill out either a factorial or response surface design space.
One way of testing multiple factors is to choose a starting point and then change the factor level in the direction of interest (Figure 1 – green dots). This is often done one variable at a time “to keep things simple”. This data can confirm an improvement in the response when any of the factors are changed individually. However, it does not tell you if making changes to multiple factors at the same time will improve the response due to synergistic interactions. With today’s complex processes, the one-factor-at-a-time experiment is likely to provide insufficient information.
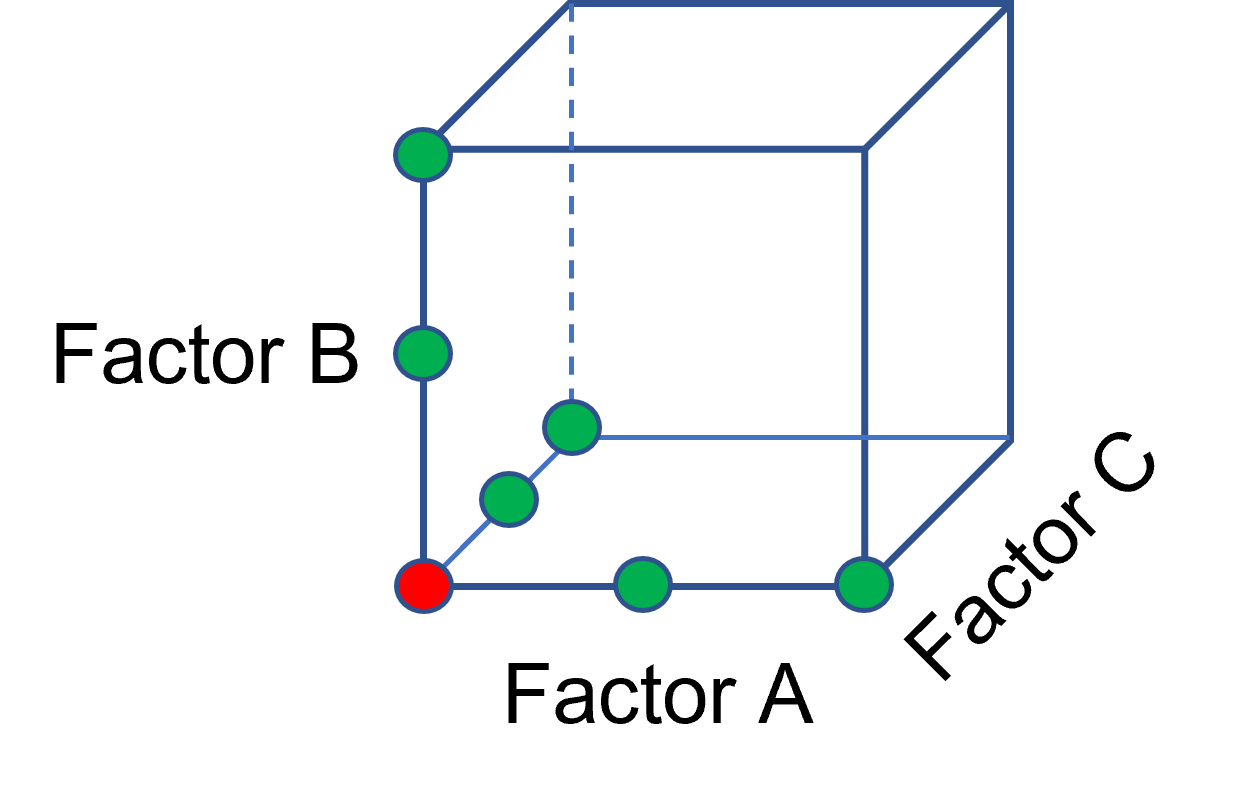
Figure 1: OFAT
The experimenter can augment the existing data by extending a factorial box/cube from the OFAT runs and completing the design by running the corner combinations of the factor levels (Figure 2 – blue dots). When analyzing this data together, the interactions become clear, and the design space is more fully explored.
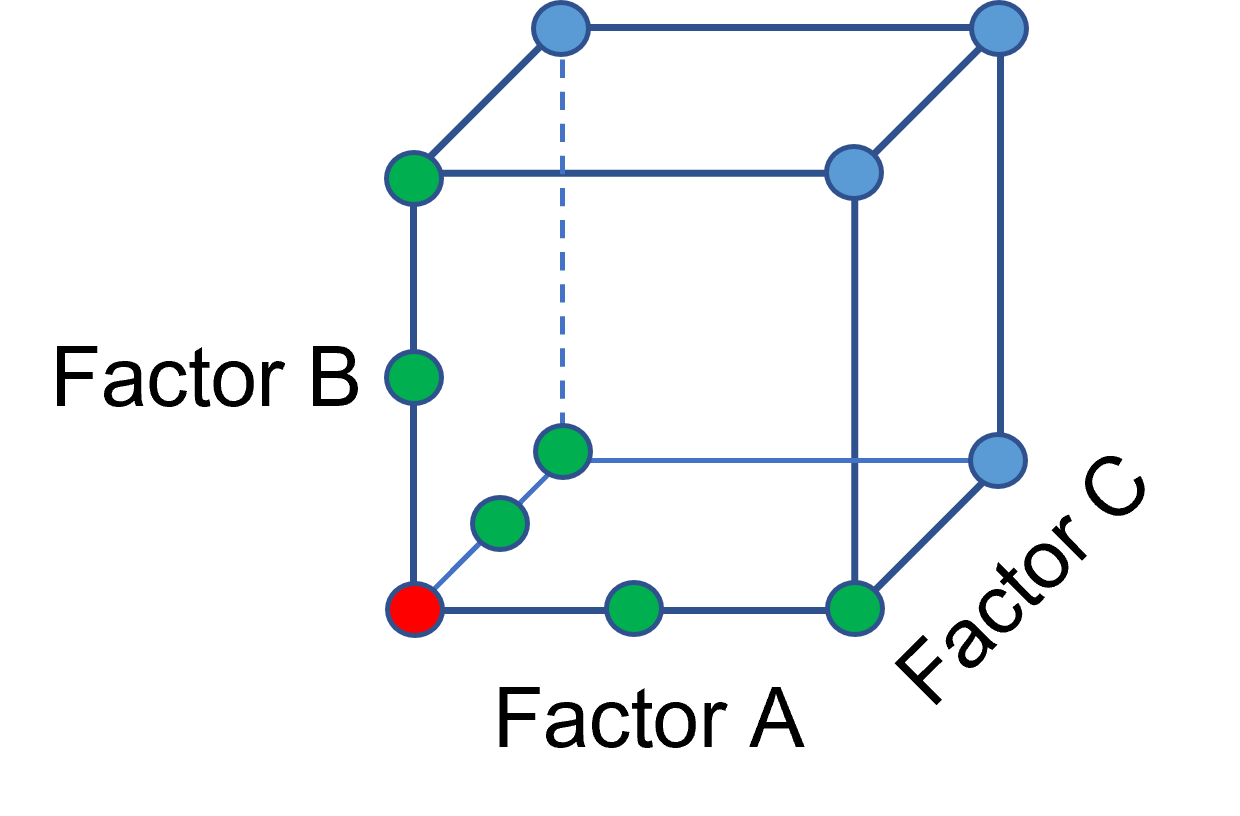
Figure 2: Fill out to factorial region
In other cases, OFAT studies may be done by taking a standard process condition as a starting point and then testing factors at new levels both lower and higher than the standard condition (see Figure 3). This data can estimate linear and nonlinear effects of changing each factor individually. Again, it cannot estimate any interactions between the factors. This means that if the process optimum is anywhere other than exactly on the lines, it cannot be predicted. Data that more fully covers the design space is required.

Figure 3: OFAT
A face-centered central composite design (CCD)—a response surface method (RSM)—has factorial (corner) points that define the region of interest (see Figure 4 – added blue dots). These points are used to estimate the linear and the interaction effects for the factors. The center point and mid points of the edges are used to estimate nonlinear (squared) terms.
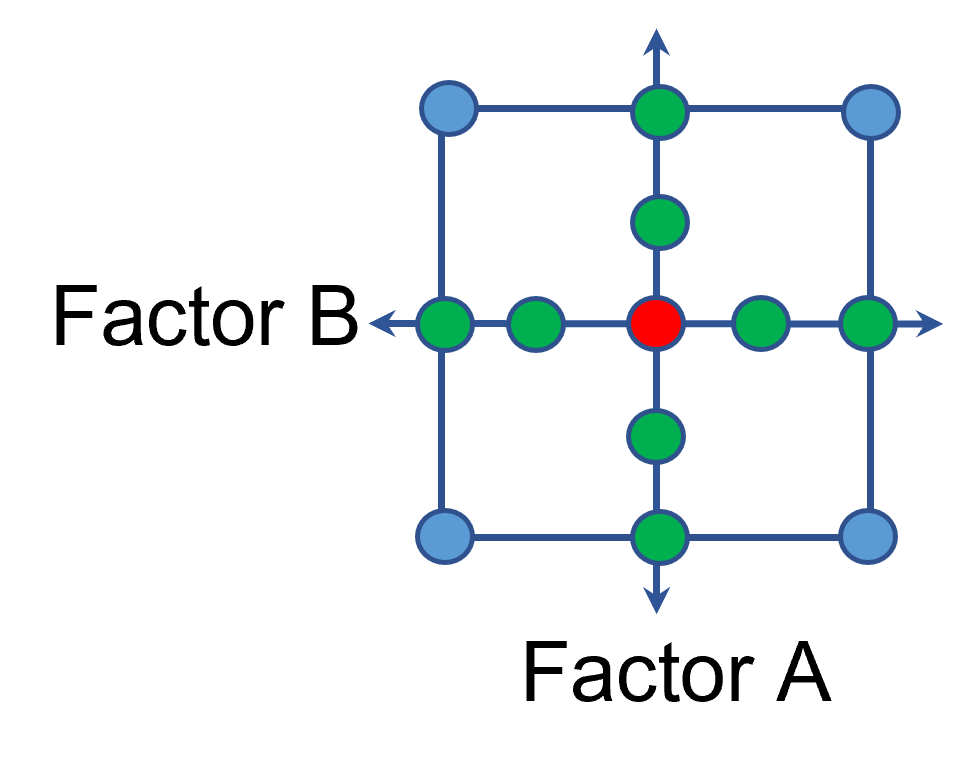
Figure 4: Face-Centered CCD
If an experimenter has completed the OFAT portion of the design, they can augment the existing data by adding the corner points and then analyzing as a full response surface design. This set of data can now estimate up to the full quadratic polynomial. There will likely be extra points from the original OFAT runs, which although not needed for model estimation, do help reduce the standard error of the predictions.
Running a statistically designed experiment from the start will reduce the overall experimental resources. But it is good to recognize that existing data can be augmented to gain valuable insights!
Learn more about design augmentation at the January webinar: The Art of Augmentation – Adding Runs to Existing Designs.
Strategy of Experiments for Formulations: Try Screening First!
Consider Screening Down Components to a Vital Few Before Studying Them In-Depth
At the outset of my chemical engineering career, I spent 2 years working with various R&D groups for a petroleum company in Southern California. One of my rotations brought me to their tertiary oil-recovery lab, which featured a wall of shelves filled to the brim with hundreds of surfactants. It amazed me how the chemist would seemingly know just the right combination of anionic, nonionic, cationic and amphoteric varieties to blend for the desired performance. I often wondered, though, whether empirical screening might have paid off by revealing a few surprisingly better ingredients. Then after settling in on the vital few components doing an in-depth experiment may very well have led to discovery of previously unknown synergisms. However, this was before the advent of personal computers and software for mixture design of experiments (DOE), and, thus, extremely daunting for non-statisticians.
Nowadays I help many formulators make the most from mixture DOE via Stat-Ease softwares’ easy-to-use statistical tools. I was very encouraged to see this 2021 meta-analysis that found 200 or so recent publications (2016-2020) demonstrating the successful application of mixture DOE for food, beverage and pharmaceutical formulation development. I believe that this number can be multiplied many-fold to extrapolate these findings to other process industries—chemicals, coatings, cosmetics, plastics, and so forth. Also, keep in mind that most successes never get published—kept confidential until patented.
However, though I am very heartened by the widespread adoption of mixture DOE, screening remains underutilized based on my experience and a very meager yield of publications from 2016 to present from a Google-Scholar search. I believe the main reasons to be:
- Formulators prefer to rely on their profound knowledge of the chemistry for selection of ingredients (refer to my story about surfactants for tertiary oil recovery)
- The number of possibilities get overwhelming; for example, this 2016 Nature publication reports that experimenters on a pear cell suspension culture got thrown off by the 65 blends they believed were required for simplex screening of 20 components (too bad, as shown in the Stat-Ease software screenshot below, by cutting out the optional check blends and constraint-plane-centroids, this could be cut back to substantially.)

- Misapplying factorial screening to mixtures, which, unfortunately happens a lot due to these process-focused experiments being simpler and more commonly used. This is really a shame as pointed out in this Stat-Ease blog post
I feel sure that it pays to screen down many components to a vital few before doing an in-depth optimization study. Stat-Ease software provides some great options for doing so. Give screening a try!!
For more details on mixture screening designs and a solid strategy of experiments for optimizing formulations, see my webinar on Strategy of Experiments for Optimal Formulation. If you would like to speak with our team about putting mixture DOE to good use for your R&D, please contact us.
Wrap-Up: Thanks for a great 2022 Online DOE Summit!
Thank you to our presenters and all the attendees who showed up to our 2022 Online DOE Summit! We're proud to host this annual, premier DOE conference to help connect practitioners of design of experiments and spread best practices & tips throughout the global research community. Nearly 300 scientists from around the world were able to make it to the live sessions, and many more will be able to view the recordings on the Stat-Ease YouTube channel in the coming months.
Due to a scheduling conflict, we had to move Martin Bezener's talk on "The Latest and Greatest in Design-Expert and Stat-Ease 360." This presentation will provide a briefing on the major innovations now available with our advanced software product, Stat-Ease 360, and a bit of what's in store for the future. Attend the whole talk to be entered into a drawing for a free copy of the book DOE Simplified: Practical Tools for Effective Experimentation, 3rd Edition. New date and time: Wednesday, October 12, 2022 at 10 am US Central time.
Even if you registered for the Summit already, you'll need to register for the new time on October 12. Click this link to head to the registration page. If you are not able to attend the live session, go to the Stat-Ease YouTube channel for the recording.

Want to be notified about our upcoming live webinars throughout the year, or about other educational opportunities? Think you'll be ready to speak on your own DOE experiences next year? Sign up for our mailing list! We send emails every month to let you know what's happening at Stat-Ease. If you just want the highlights, sign up for the DOE FAQ Alert to receive a newsletter from Engineering Consultant Mark Anderson every other month.
Thank you again for helping to make the 2022 Online DOE Summit a huge success, and we'll see you again in 2023!