Stat-Ease Blog

Categories
Greg's DOE Adventure - Factorial Design, Part 2
[Disclaimer: I’m not a statistician. Nor do I want you to think that I am. I am a marketing guy (with a few years of biochemistry lab experience) learning the basics of statistics, design of experiments (DOE) in particular. This series of blog posts is meant to be a light-hearted chronicle of my travels in the land of DOE, not be a text book for statistics. So please, take it as it is meant to be taken. Thanks!]
Keep your experiment planned, but random
When I wrote my introduction to factorial design (Greg’s DOE Adventure - Factorial Design, Part 1), there were a couple of points that I left out. I’ll amend that post here to talk about making sure your experiment is planned out yet random.
Wait. What?
You’ll see. Let me explain.
Getting organized
During the initial phase of an experiment, you should make sure that it is well planned out. First, think about the factors that affect the outcome of your experiment. You want to create a list that’s as all-encompassing as possible. Anything that may change the outcome, put on your list. Then pare it down into the ones that you know are going to be the biggest contributors.
Once you have done that, you can set the levels at which to run each factor. You want the low and high levels to be as far apart as possible. Not too low that you won’t see an effect (if your experiment is cooking something, don’t set the temperature so low that nothing happens). Not too high that it’s dangerous (as in cooking, you don’t want to burn your product).
Finally, you want to make sure your experiment is balanced when it comes to the factors in your experiment. Taking the cooking example above a little further, suppose you have three factors you are testing: time, temperature, and ingredient quality. Let’s also say that you are testing at two different levels: low and high (symbolized by minus and plus signs, respectively). We can write this out in a table:
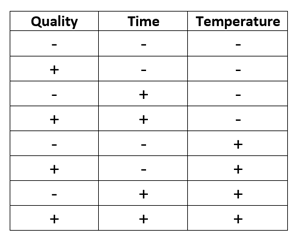
This table contains all the possible combinations of the three factors. It’s called an ‘orthogonal array’ because it’s balanced. Each column has the same number of pluses and minuses (4 in this case). This balance in the array allows all factors to be uncorrelated and independent from each other.
With these steps, you have ensured that your experiment is well planned out and balanced when looking at your factors.
Always randomize
At the start of this post, I said that an experiment should be planned out, yet random. Well we have the planned-out part, now let’s get into the random part.
In any experimentation, influence from external sources (variables you are not studying) should be kept to a minimum. One way to do this is randomizing your runs.
As an example, let’s look at the table above with the cooking example. Let’s say that it represents the order of how the experiment was run. So, all the low temperature runs were made together and then all the high ones together. This makes sense, right? Perform all the runs at one temperature before adjusting up to the next setting.
The problem is, what if there is an issue with your oven that causes the temperature to fluctuate more, early in the experiment and less later. This time-related issue introduces variation (bias) into your results that you didn’t know about.
To reduce the influence of this variable, randomize your run order. It may take more time adjusting your oven for every run, but it will remove that unwanted variation.
Temperature is a popular example to illustrate randomization. But this can be said of any factor that may have time-related problems. It could be warm-up time on a machine or the physical tiring of an operator. Randomization is used to guard against bias as much as you can when running an experiment.
Conclusions
Hopefully, you see now why I said to keep your experiments planned but random. It sounds like an oxymoron, but it’s not. Not in the way I’m talking about it here!
Stat-Ease - Here for You
Stat-Ease is here for you during these trying times. We can help you with your design and analysis of experiments, whether at home or in the lab. Please reach out if you have a question, sales@statease.com
A summary of information that may be important to you
Access to Design-Expert® software while working at home:
- Download a free trial at www.statease.com/trial/. (Used your DX12 trial already? Ask us!)
- Network users - temporarily bring a license home by checking out a roaming license from your server. Go to www.statease.com/docs/v12/network-installation/#roaming-licenses for more information.
- Need Technical Assistance? Email support@statease.com
Access to FREE educational materials:
- Elearning - learn DOE on demand at the Stat-Ease Academy. Go to www.statease.com/training/academy/ to sign up.
- Hear from our DOE experts: visit our Webinars page at www.statease.com/webinars/ and our YouTube channel, www.youtube.com/channel/UCzf_5--odkQ4w25m5r09bWA
- Dive into Design-Expert software: Tutorials (www.statease.com/docs/v12/tutorials/)
2020 European Conference: Our conference (www.statease.com/events/doe-user-meetings/8th-european-doe-meeting/) is being re-imagined into an online opportunity that will be accessible to our global audience!
To receive information by email, go to www.statease.com/publications/signup/ and signup for our email list.
If you have other needs while transitioning to a new work setup, or an Academic online learning environment, please contact sales@statease.com
Background on the KCV Designs
Design-Expert® software, v12 offers formulators a simplified modeling option crafted to maximize essential mixture-process interaction information, while minimizing experimental costs. This new tool is nicknamed a “KCV model” after the initials of the developers – Scott Kowalski, John Cornell, and Geoff Vining. Below, Geoff reminisces on the development of these models.
To help learn this innovative methodology, first view a recorded webinar on the subject.
Next, sign up for the workshop "Mixture Design for Optimal Formulations".
The origin of the KCV designs goes back to a mixtures short-course that I taught for Doug Montgomery at an adhesives company in Ohio. One of the topics was mixture-process variables experiments, and Doug's notes for the course contained an example using ratios of mixture proportions with the process variables. Looking at the resulting designs, I recognized that ratios did not cover the mixture design space well. Scott Kowalski was beginning his dissertation at the time. Suddenly, he had a new chapter (actually two new chapters)!
The basic idea underlying the KCV designs is to start with a true second-order model in both the mixture and process variables and then to apply the mixture constraint. The mixture constraint is subtle and can produce several models, each with a different number of terms. A fundamental assumption underlying the KCV designs is that the mixture by process variable interactions are of serious interest, especially in production. Typically, corporate R&D develops the basic formulation, often under extremely pristine conditions. Too often, R&D makes the pronouncement that "Thou shall not play with the formula." However, there are situations where production is much smoother if we can take advantage of a mixture component by process variable interaction that improves yields or minimizes a major problem. Of course, that change requires changing the formula.
Cornell (2002) is the definitive text for all things dealing with mixture experiments. It covers every possible model for every situation. However, John in his research always tended to treat the process variables as nuisance. In fact, John's intuitions on Taguchi's combined array go back to the famous fish patty experiment in his book. The fish patty experiment looked at combining three different types of fish and involved three different processing conditions. John's intuition was how to create the best formulation robust to the processing conditions, recognizing that the use of these fish patties was in a major fast-food chain. The processing conditions in actual practice typically were in the hands of teenagers who may or may not follow the protocol precisely.
John's basic instincts followed the corporate R&D-production divide. He rarely, if ever, truly worried about the mixture by process variable interactions. In addition, his first instinct always was to cross a full mixture component experiment with a full factorial experiment in the process variables. If he needed to fractionate a mixture-process experiment, he always fractionated the process variable experiment, because it primarily provided the "noise".
The basic KCV approach reversed the focus. Why can we not fractionate the mixture experiment in such a way that if a process variable is not significant, the resulting design projects down to a standard full mixture experiment? In the process, we also can see the impact of possible mixture by process variable interactions.
I still vividly remember when Scott presented the basic idea in his very first dissertation committee meeting. Of course, John Cornell was on Scott's committee. In Scott's first committee meeting, he outlined the full second-order model in both the mixture and process variables and then proceeded to apply the mixture constraint in such a way as to preserve the mixture by process variable interactions. John, who was not the biggest fan of optimal designs when a standard mixture experiment would work well, immediately jumped up and ran to the board where Scott was presenting the basic idea. John was afraid that we were proposing to use this model and apply our favorite D-optimal algorithm, which may or may not look like a standard mixture design. John and I were very good friends. I simply told him to sit down and wait a few minutes. He reluctantly did. Five minutes later, Scott presented our design strategy for the basic KCV designs, illustrating the projection properties where if a process variable was unimportant the mixture design collapsed to a standard full mixture experiment. John saw that this approach addressed his basic concerns about the blind use of an optimal design algorithm. He immediately became a convert, hence the C in KCV. He saw that we were basically crossing a good design in the process variables, which itself could be a fraction, with a clever fraction of the mixture component experiment.
John's preference to cross a mixture experiment with a process variable design meant that it was very easy to extend these designs to split-plot structures. As a result, we had two very natural chapters for Scott's dissertation. The first paper (Kowalski, Cornell, and Vining 2000) appeared in Communications in Statistics in a special issue guest edited by Norman Draper. The second paper (Kowalski, Cornell, and Vining 2002) appeared in Technometrics.
There are several benefits to the KCV design strategy. First, these designs have very nice projection properties. Of course, they were constructed specifically to achieve this goal. Second, it can significantly reduce the overall design size while still preserving the ability to estimate highly informative models. Third, unlike the approach that I taught in Ohio, the KCV designs cover the mixture experimental design space much better while still providing the equivalent information. The underlying models for both approaches are equivalent.
It has been very gratifying to see Design-Expert incorporate the KCV designs. We hope that Design-Expert users find them valuable.
References
Cornell, J.A. (2002). Experiments with Mixtures: Designs, Models, and the Analysis of Mixture Data, 3rd ed. NewYork: John Wiley and Sons.
Kowalski, S.M., Cornell, J.A., and Vining, G.G. (2000). “A New Model and Class of Designs for Mixture Experiments with Process Variables,” Communications in Statistics – Theory and Methods, 29, pp. 2255-2280.
Kowalski, S.M., Cornell, J.A., and Vining, G.G. (2002). “Split-Plot Designs and Estimation Methods for Mixture Experiments with Process Variables,” Technometrics, 44, pp. 72-79.
Experimental Design in Chemistry: A Review of Pitfalls (Guest Post)
This blog post is from James Cawse, Consultant and Principal at Cawse and Effect, LLC. Jim uses his unique blend of chemical knowledge, statistical skills, industrial process experience, and quality commitment to find solutions for his client's difficult experimental and process problems. He received his Ph.D. in Organic Chemistry from Stanford University. On top of all that, he's a great guy! Visit his website (link above) to find out more about Jim, his background, and his company.
Introduction
Getting the best information from chemical experimentation using design of experiments (DOE) is a concept that has been around for decades, although it is still painfully underused in chemistry. In a recent article Leardi1 pointed this out with an excellent tutorial on basic DOE for chemistry. The classic DOE text Statistics for Experimenters2 also used many chemical illustrations of DOE methodology. In my consulting practice, however, I have encountered numerous situations where ’vanilla‘ DOE – whether from a book, software, or a Six Sigma course – struggles mightily because of the inherent complications of chemistry.The basic rationale for using a statistically based DOE in any science are straightforward. The DOE method provides:
- Points distributed in a rational fashion throughout “experimental space”.
- Noise reduction by averaging and application of efficient statistical tools.
- ‘Synergy’, typically the result of the interactions of two or more factors - easily determined in a DOE.
- An equation (model) that can then be used to predict further results and optimize the system.
DOE works so well in most scientific disciplines because Mother Nature is kind. In general:
- Most experiments can be performed with small numbers of ’well behaved‘ factors, typically simple numeric or qualitative at 2-3 levels
- Interactions typically involve only 2 factors. Three level and higher interactions are ignored.
- The experimental space is relatively smooth; there are no cliffs (e.g. phase changes).
Y = B0 + B1x1 + B2x2 + B12x1x2 + B11x12 +…
In contrast, chemistry offers unique challenges to the team of experimenter and statistician. Chemistry is a science replete with nonlinearities, complex interactions, and nonquantitative factors and responses. Chemical experiments require more forethought and better planning than most DOE’s. Chemistry-specific elements must be considered.
Mixtures
Above all, chemists make mixtures of ‘stuff’. These may be catalysts, drugs, personal care items, petrochemicals, or others. A beginner trying to apply DOE to a mixture system may think to start with a conventional cubic factorial design. It soon becomes clear, however, that there is an impossible situation when the (+1, +1, +1) corner requires 100% of A and B and C! The actual experimental space of a mixture is a triangular simplex. This can be rotated into the plane to show a simplex design, and it can easily be extended to high dimensions such as a tetrahedron.
It is rare that a real mixture experiment will actually use 100% of the components as points. A real experiment with be constrained by upper and lower bounds, or by proportionality requirements. The active ingredients may also be tiny amounts in a solvent. The response to a mixture may be a function of the amount used (fertilizers or insecticides, for example). And the conditions of the process which the mixture is used in may also be important, as in baking a cake – or optimizing a pharmaceutical reaction. All of these will require special designs.
Fortunately, all of these simple and complex mixture designs have been extensively studied and are covered by Cornell3, Anderson et al4, and Design-Expert® software.
Kinetics
The goal of a kinetics study is an equation which describes the progress of the reaction. The fundamental reality of chemical kinetics is
Rate = f(concentrations, temperature).
However, the form of the equation is highly dependent on the details of the reaction mechanism! The very simplest reaction has the first-order form
Rate = k*C1
which is easily treated by regression. The next most complex reaction has the form
Rate = k*C1*C2
in which the critical factors are multiplied – no longer the additive form of a typical linear model. The complexity continues to increase with multistep reactions.
Catalysis studies are chemical kinetics taken to the highest degree of complication! In industry, catalysts are often improved over years or decades. This process frequently results in increasingly complex catalyst formulations with components which interact in increasingly complex ways. A basic catalyst may have as many as five active co-catalysts. We now find multiple 2-factor interactions pointing to 3-factor interactions. As the catalyst is further refined, the Law of Diminishing Returns sets in. As you get closer to the theoretical limit – any improvement disappears in the noise!
Chemicals are not Numbers
As we look at the actual chemicals which may appear as factors in our experiments, we often find numbers appearing as part of their names. Often the only difference among these molecules is the length of the chain (C-12, 14, 16, 18) and it is tempting to incorporate this as numeric levels of the factor. Actually, this is a qualitative factor; calling it numeric invites serious error! The correct description, now available in Design-Expert, is ’Discrete Numeric’.
The real message, however, is that the experimenters must never take off their ’chemist hat‘ when putting on a ’statistics hat’!
Reference Materials:
- Leardi, R., "Experimental design in chemistry: A tutorial." Anal Chim Acta 2009, 652 (1-2), 161-72.
- Box, G. E. P.; Hunter, J. S.; Hunter, W. G., Statistics for Experimenters. 2nd ed.; Wiley-Interscience: Hoboken, NJ, 2005.
- Cornell, J. A., Experiments with Mixtures. 3rd ed.; John Wiley and Sons: New York, 2002.
- Anderson, M.J.; Whitcomb, P.J.; Bezener, M.A.; Formulation Simplified; Routledge: New York, 2018.
Greg’s DOE Adventure - Factorial Design, Part 1
[Disclaimer: I’m not a statistician. Nor do I want you to think that I am. I am a marketing guy (with a few years of biochemistry lab experience) learning the basics of statistics, design of experiments (DOE) in particular. This series of blog posts is meant to be a light-hearted chronicle of my travels in the land of DOE, not be a text book for statistics. So please, take it as it is meant to be taken. Thanks!]
So, I’ve gotten thru some of the basics (Greg's DOE Adventure: Important Statistical Concepts behind DOE and Greg’s DOE Adventure - Simple Comparisons). These are the ‘building blocks’ of design of experiments (DOE). However, I haven’t explored actual DOE. I start today with factorial design.
We can illustrate like this:
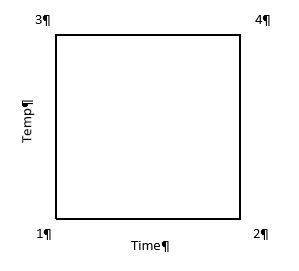
In this case, the horizontal line (x-axis) is time and vertical line (y-axis) is temperature. The area in the box formed is called the Experimental Space. Each corner of this box is labeled as follows:
1 – low time, low temperature (resulting in crunchy, matchstick-like pasta), which can be coded minus-minus (-,-)
2 – high time, low temperature (+,-)
3 – low time, high temperature (-,+)
4 – high time, high temperature (making a mushy mass of nasty) (+,+)
One takeaway at this point is that when a test is run at each point above, we have 2 results for each level of each factor (i.e. 2 tests at low time, 2 tests at high time). In factorial design, the estimates of the effects (that the factors have on the results) is based on the average of these two points; increasing the statistical power of the experiment.
Power is the chance that an effect will be found, when there is an effect to be found. In statistical speak, power is the probability that an experiment correctly rejects the null hypothesis when the alternate hypothesis is true.
If we look at the same experiment from the perspective of altering just one factor at a time (OFAT), things change a bit. In OFAT, we start at point #1 (low time, low temp) just like in the Factorial model we just outlined (illustrated below).
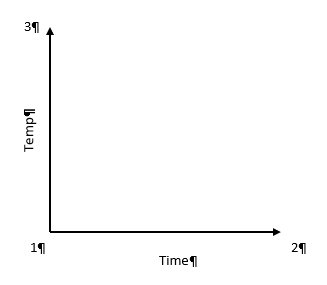
Here, we go from point #1 to #2 by lengthening the time in the water. Then we would go from #1 to #3 by changing the temperature. See how this limits the number of data points we have? To get the same power as the Factorial design, the experimenter will have to make 6 different tests (2 runs at each point) in order to get the same power in the experiment.
After seeing these results of Factorial Design vs OFAT, you may be wondering why OFAT is still used. First of all, OFAT is what we are taught from a young age in most science classes. It’s easy for us, as humans, to comprehend. When multiple factors are changed at the same time, we don’t process that information too well. The advantage these days is that we live in a computerized world. A computer running software like Design-Expert®, can break it all down by doing the math for us and helping us visualize the results.
Additionally, with the factorial design, because we have results from all 4 corners of the design space, we have a good idea what is happening in the upper right-hand area of the map. This allows us to look for interactions between factors.
That is my introduction to Factorial Design. I will be looking at more of the statistical end of this method in the next post or two. I’ll try to dive in a little deeper to get a better understanding of the method.